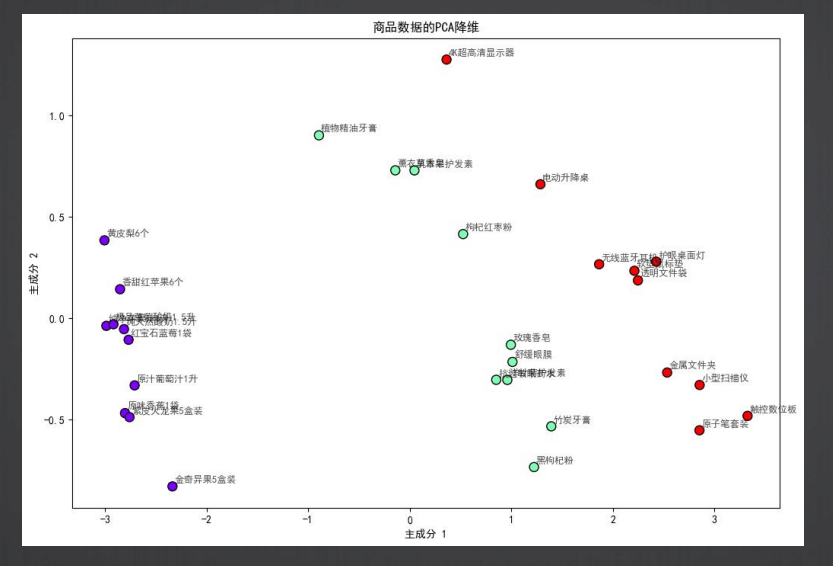
“归类分析”(Cluster Analysis)是一种无监督学习方法,它用于在数据集中发现内在的结构或模式,通过将数据对象分组(称为聚类)来实现。在归类分析中,相似的对象被归入同一个群组,而不同的对象则被分配到不同的群组。这种方法不依赖于预先定义的类别,而是通过算法自动发现数据的自然分组。
归类分析的应用非常广泛,包括市场细分、社交网络分析、生物信息学、图像分割、文本挖掘等领域。常见的归类分析算法有K-均值聚类(K-means clustering)、层次聚类(Hierarchical clustering)、密度聚类(如DBSCAN)等。
在进行归类分析时,通常需要考虑以下几个步骤:
- 数据预处理:包括数据清洗、标准化或归一化,以消除不同量纲对聚类结果的影响。
- 选择聚类算法:根据数据的特性和分析目标选择合适的聚类算法。
- 确定聚类数量:对于某些算法(如K-means),需要预先指定聚类的数量。
- 执行聚类:运行所选算法对数据进行聚类。
- 结果评估:评估聚类的质量,这可能包括内部评价指标(如轮廓系数)和外部评价指标(如果可用)。
- 结果解释:对聚类结果进行分析,理解每个群组的特征,并可能对数据进行进一步的分析。
归类分析的挑战之一是如何确定最佳的聚类数量,以及如何解释聚类结果。此外,对于高维数据,传统的聚类算法可能会遇到“维度灾难”,这时可能需要降维技术(如主成分分析PCA)来辅助聚类分析。

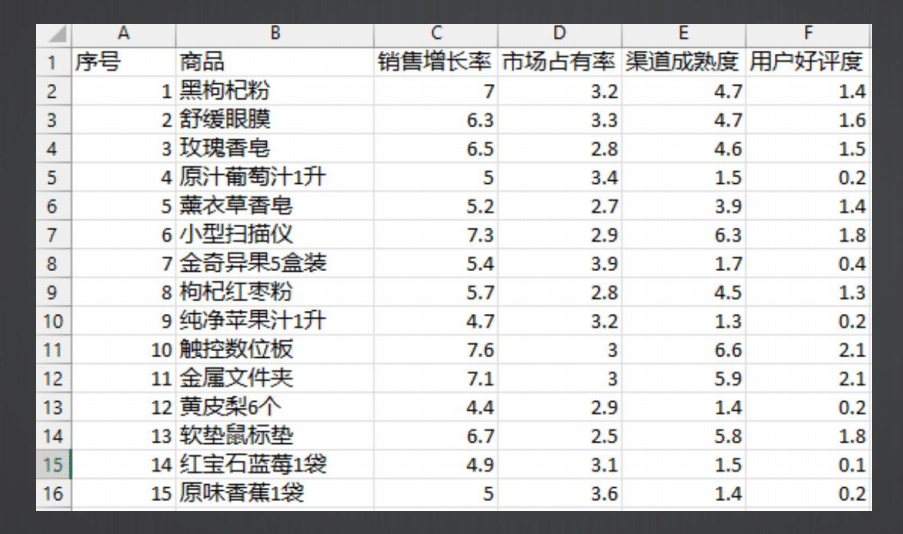
数据:
模型:

归类: